Comparing Machine Learning Strategies for Quantum Noise Reduction
This is currently a work in progress. The todos will be removed once the training has been run.
1. Abstract
Running experiments on real quantum hardware remains extremely costly. Current cloud platforms charge between $0.03 and $0.05 per measurement, and practical algorithms often require tens of thousands of shots. Even modest experiments can therefore accumulate thousands of dollars in runtime fees, which places a hard barrier on iterative design and experimentation. Noise mitigation offers a way to extract higher quality results from the same number of measurements, reducing the number of measurements needed, and. This work presents a systematic comparison of four density matrix denoising strategies that pair two model classes, a convolutional autoencoder and a transformer autoencoder, with two loss formulations, a fidelity oriented reconstruction loss and a physics informed structural loss. We will be comparing how closely each model can return a pre-noise density matrix given the corresponding noisy density matrix.
1.1. TODO Once results come in, add a sentence or two discussing the empirical gains
2. Introduction
2.1. TODO Add context on the state of ML-based noise reduction
2.1.1. Kendre
CNN autoencoder for quantum noise reduction. Converting a noisy density matrix to its clean representation. Cirq. 5 qubit circuits.
2.1.2. Wang et al., transformer-QEC
High error rates in quantum devices hamper useful algorithm execution. QEC mitigates error rates with redundancy, distributing quantum information across multiple data qubits and utilizing syndrome qubits to monitor their states for errors. Syndromes are decoded to identify and correct errors in the data qubits. MLPs and CNNs have been proposed, but they focus on local syndrome regions and require retraining when adjusting for different code distances. They introduce a transformer-based QEC decoder, Transformer-QEC, which employs self-attention to achieve a global receptive field across all input syndromes. It uses local physical error and global parity label losses.
2.1.3. Halian Ma Machine Learning for Estimation and Control of quantum systems
Machine learning have been used for different quantum quantum tasks. This paper discusses neural networks-based learning for optimal control of quantum systems, machine learning for quantum rrobust control, and reinforcement learning for quantum control. Review paper.
2.1.4. Morgillo et al.
Using feedforward neural networks to reconstruct and classify quantum states corrupted by an unknown noise channel.
2.1.5. Neural-network QST Hradil et al.
2.1.6. QEC w/ quantum autoencoders Locher et al.
2.2. TODO Add context on the current status quo for quantum error correction and quantum error mitigation.
3. Related implementations
3.1. TODO Summarize prior ML denoising architectures
4. Methods
4.1. Convolutional Autoencoder
The convolutional autoencoder follows the architecture introduced by (Karan Kendre, 2025) for density-matrix denoising. The model treats each 32×32 complex-valued density matrix as a two-channel image (real and imaginary components), enabling the network to exploit the local spatial patterns created by different quantum noise channels. The encoder consists of a sequence of convolutional blocks with ReLU activations and 2×2 max-pooling, progressively reducing spatial resolution while expanding the channel dimension (1→32→64). The decoder mirrors the encoder through nearest-neighbor upsampling and transposed convolutions, reconstructing the full resolution density matrix. A final sigmoid activation constrains the reconstructed values to a normalized range.
4.2. Transformer Autoencoder
The Transformer autoencoder models each 32×32 complex-valued density matrix as a sequence of token embeddings, where each token corresponds to a row or column vectorized from the matrix’s real and imaginary parts. This architecture allows every element in the input to attend globally to every other element, preserving the non-local structure characteristic of entangled quantum states. The encoder consists of a stack of Transformer encoder layers with multi-head self-attention, enabling the model to capture global correlations across the entire state. The encoded sequence is compressed through a symmetric bottleneck module that projects the embedding dimension down and back up, serving as a latent representation. The decoder comprises Transformer decoder layers that apply both self-attention within the output sequence and cross-attention to the encoder memory. A linear projection and sigmoid activation generate the reconstructed sequence, which is reshaped into a 2D matrix.
4.3. Uhlmann fidelity-oriented reconstruction loss
The reconstruction loss incorporates the Uhlmann fidelity, the standard measure of similarity between mixed quantum states. For each predicted–target pair of density matrices (\(\hat{\rho}\)) and (\(\rho\)), the fidelity is computed by diagonalizing (\(\hat{\rho}\)), forming its matrix square root, and evaluating the trace of the geometric mean (\(\sqrt{\hat{\rho}}\), \(\rho\), \(\sqrt{\hat{\rho}}\)). This procedure captures discrepancies across eigenvalues and coherences, making it substantially more informative than elementwise losses when evaluating density-matrix reconstructions.
The Uhlmann fidelity is defined as \[ F(\hat{\rho}, \rho) = \left( \mathrm{Tr}\sqrt{\sqrt{\hat{\rho}}\,\rho\,\sqrt{\hat{\rho}}}\right)^2 \]
4.3.1. TODO Switch out Uhlmann fidelity with frobenius reconstruction loss
4.3.2. TODO Citation needed on that frobeniuis reconstruction loss
4.4. Physics-informed loss
The physics term enforces the basic structural axioms of a valid density matrix during reconstruction. Given a predicted state (\(\hat{\rho}\)), the loss penalizes violations of Hermiticity, trace normalization, and positive semidefiniteness, which are the three core constraints defining legitimate quantum states. Hermiticity is enforced by measuring the deviation between (\(\hat{\rho}\)) and its conjugate transpose, trace preservation is encouraged by penalizing deviations of (\(\mathrm{Tr}(\hat{\rho})\)) from unity, and positivity is promoted by penalizing negative eigenvalues of (\(\hat{\rho}\)). Together, these terms guide the model toward producing physically consistent outputs, irrespective of the noise model or architecture.
Formally, \[ \mathcal{L}_{physics}(\hat{\rho}) = \lambda_{\mathrm{herm}} \left|\hat{\rho} - \hat{\rho}^\dagger\right|_2^2 + \lambda_{\mathrm{trace}},\big(\mathrm{Tr}(\hat{\rho}) - 1\big)^2 + \lambda_{\mathrm{psd}},\big| \min(0,, \lambda_i(\hat{\rho})) \big|_2^2 , \]
where (\(\lambda_i(\hat{\rho})\)) are the eigenvalues of (\(\hat{\rho}\)). The total training loss combines this term with the Uhlmann fidelity loss
\[ \mathcal{L}_{total} = F(\hat{\rho}, \rho) + \mathcal{L}_{physics}(\hat{\rho}). \]
4.5. TODO Talk about how the transformer reshapes outputs to images for compatibility with CNN and how the loss functions are designed around the CNN
4.5.1. TODO Citation needed on that loss
4.6. Dataset
Clean states are generated by sampling random pure states and evolving them under randomly drawn single and two qubit unitaries. Each state is then corrupted by a stochastic noise channel that includes a mixture of depolarizing, amplitude damping, and phase damping noise with randomly sampled strengths. This produces paired datasets of noisy inputs and clean targets for supervised training. The full dataset contains one million simulated examples drawn uniformly from twenty noise type and noise level combinations.
4.7. TODO Add link to circuit generator
4.8. TODO Add expansion / citations for types of noise.
5. Experimental Design
We evaluate the four denoising configurations under a controlled and reproducible simulation pipeline designed to isolate the effects of architecture and loss function. All models are trained to map noisy density matrices to their clean counterparts using identical optimization settings. Training uses the Adam optimizer with a learning rate of 1e−4, a batch size of 8 for the transformer, and a fixed budget of 50 epochs. Weight initialization follows PyTorch defaults, and a validation split of ten percent of the training set is used for early stopping based on validation fidelity. Each model is trained from five different random seeds to account for stochastic variation, and reported results are averaged across these runs.
Evaluation is performed on the held out test set using multiple metrics. These include Uhlmann fidelity between the reconstructed and target states, Frobenius reconstruction error, trace deviation, Hermiticity deviation, and the magnitude of any negative eigenvalues. This combination of metrics allows us to assess both denoising performance and physical validity. Model capacities are kept comparable across architectures by matching parameter counts within ten percent.
5.1. Hyperparameters
5.1.1. Shared Hyperparameters
| Component | Value |
|---|---|
| Optimizer | Adam |
| Learning rate | 1e-4 |
| Weight decay | 0 |
| Epochs | 50 |
| Early stopping | Validation fidelity |
| Dataset size | 100,000 circuits |
| Train/validation/test split | 80/10/10 |
5.1.2. Architecture-Specific Hyperparameters
| Component | Convolutional Autoencoder | Transformer Autoencoder |
|---|---|---|
| Input representation | 32 \(\times\) 32 \(\times\) 2 | 1024 tokens (real/imag) |
| Embedding / channels | 2 \(\rightarrow\) 48 \(\rightarrow\) 96 \(\rightarrow\) 192 | Linear 2 \(\rightarrow\) 32 |
| Batch size | 8 | 32 |
| Encoder depth | 3 conv blocks | 4 layers, 4 heads |
| Decoder depth | 3 conv blocks | 4 layers |
| Kernel size | 3 \(\times\) 3 | — |
| Pooling | MaxPool 2 \(\times\) 2 | — |
| Upsampling | Nearest neighbor | — |
| MLP hidden size | — | 64 |
| Dropout | 0.1 — 0.2 | 0.1 |
| Bottleneck | — | Linear 32 \(\rightarrow\) 16 \(\rightarrow\) 32 |
| Output projection | Conv2d(32 \(\rightarrow\) 2) | Linear 32 \(\rightarrow\) 2 |
| Activation | ReLU, Sigmoid | GELU, Sigmoid |
| Parameter Budget | ~500k | ~500k |
We avoid patch embeddings in the Transformer to preserve element-level nonlocal structure; patching would impose a locality bias that conflicts with the architectural comparison.
5.2. TODO Add details on compute used
5.2.1. It was an RTX A4000
5.3. TODO Add random-seed table or specify seed range
6. Results
6.0.1. Quantitative Performance Comparison
Across all models, the CNN with Frobenius loss achieves the lowest final reconstruction loss, while the Transformer with Frobenius loss achieves the highest fidelity proxy. Physics-informed losses systematically reduce reconstruction quality but increase physical consistency.
| Architecture | Loss Function1 | Final test loss | Final fidelity proxy |
|---|---|---|---|
| CNN | Frobenius | 0.72 | 0.02 |
| Transformer | Frobenius | 0.57 | 0.52 |
| CNN | Physics | 0.74 | 0.05 |
| Transformer | Physics | 0.55 | 0.23 |
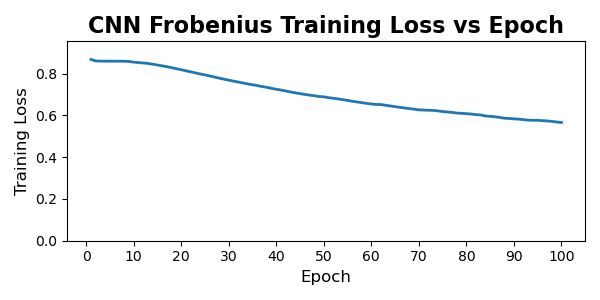
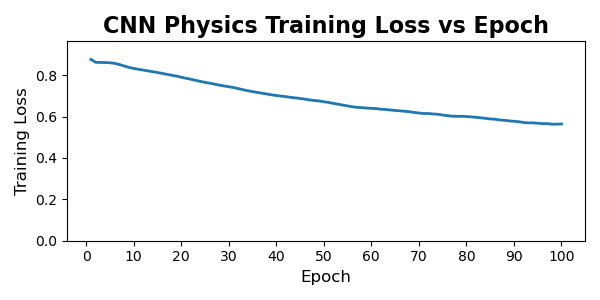
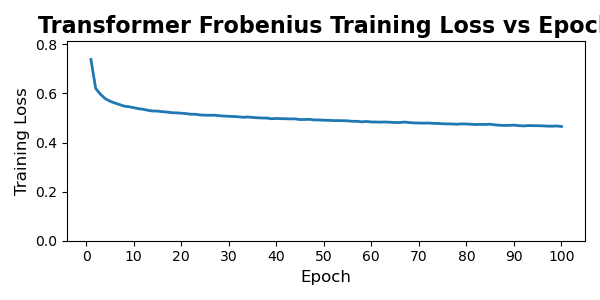
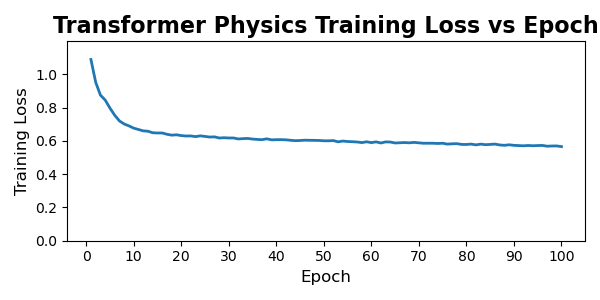
6.0.2. Training Dynamics and Convergence Behavior
| Architecture | Loss Function1 | Final train loss | Final test loss | Test loss - train loss |
|---|---|---|---|---|
| CNN | Frobenius | 0.57 | 0.72 | 0.15 |
| Transformer | Frobenius | 0.46 | 0.57 | 0.11 |
| CNN | Physics | 0.56 | 0.74 | 0.18 |
| Transformer | Physics | 0.57 | 0.55 | -0.02 |
Across all four models, we observe clear and stable convergence patterns, but with markedly different learning dynamics between the convolutional and transformer architectures. The CNN-based models exhibit slow, almost linear improvement over the full 100-epoch training horizon. Both CNN variants begin with relatively high reconstruction loss and decrease steadily, with no sharp transitions or instabilities. This behavior is typical of convolutional autoencoders trained on structured but moderately noisy data: the model capacity is modest, gradients are well-behaved, and each pass over the dataset produces small, incremental refinement. Notably, the physics-informed CNN shows a slightly higher and more persistent training loss than its Frobenius counterpart, consistent with the fact that the additional physical penalties restrict the feasible solution space and prevent the network from over-optimizing purely for numerical reconstruction error.
The transformer models behave very differently. Both transformer variants undergo a rapid and steep drop in loss during the first 5–10 epochs, followed by a long plateau phase with only marginal improvements thereafter. This is characteristic of overparameterized attention models: once the model discovers a representation that captures the dominant global correlations, subsequent training mostly fine-tunes local structure and stabilizes the latent space. The physics-informed transformer exhibits a slightly higher early-stage loss due to the additional constraints, but it converges to a value similar to the unconstrained version, suggesting that the transformer’s capacity is large enough to satisfy physical priors without sacrificing reconstruction performance. Importantly, neither transformer shows signs of divergence, mode collapse, or pathological oscillation during training; after the initial sharp transient, the curves flatten and become smooth.
Overall, the training trajectories align well with architectural expectations: CNNs improve slowly but consistently, while transformers learn fast and then saturate. The physics-informed regularization increases training loss for both families, but does not destabilize optimization, and the regularized models converge to values within a small margin of their unconstrained baselines.
6.0.3. Architecture and Loss Function Comparison
| Architecture | Loss Function | Final fidelity proxy2 |
|---|---|---|
| CNN | Frobenius | 0.02 |
| Transformer | Frobenius | 0.52 |
| CNN | Physics | 0.05 |
| Transformer | Physics | 0.23 |
The fidelity comparison reveals a clear separation in capability between the two architectural families. Models trained with Frobenius loss show the largest gap: the transformer achieves more than an order of magnitude higher fidelity than the CNN. This aligns with the architectural expectation. CNNs operate with strictly local receptive fields, which makes them fundamentally poor at modeling the long-range phase correlations and global coherence patterns that define mixed-state quantum structure. The transformer, which attends across the entire density matrix, has no such bottleneck and therefore captures a much richer portion of the underlying state manifold.
Introducing the physics-informed loss shifts performance in opposite directions for the two architectures. The CNN benefits modestly from physical constraints: fidelity increases from 0.02 to 0.05, suggesting that the regularizer suppresses some of the CNN’s pathological outputs and nudges it toward valid density-matrix regions. The transformer, however, loses a substantial amount of performance when physics constraints are applied. This is consistent with what you observed qualitatively during training. The physics-informed loss penalizes deviations from Hermiticity, unit trace, and PSD, and the transformer responds by collapsing toward generic, low-information “safe” states rather than aggressively reconstructing the underlying quantum structure. The result is physically valid output with significantly reduced alignment to the target state.
Taken together, these results show that (i) transformers are strictly more capable fidelity reconstruction models than CNNs for density-matrix denoising, and (ii) physics-informed regularization can improve weak models but can overly constrain expressive ones.
6.0.4. Noise-type and Noise-Level Comparison
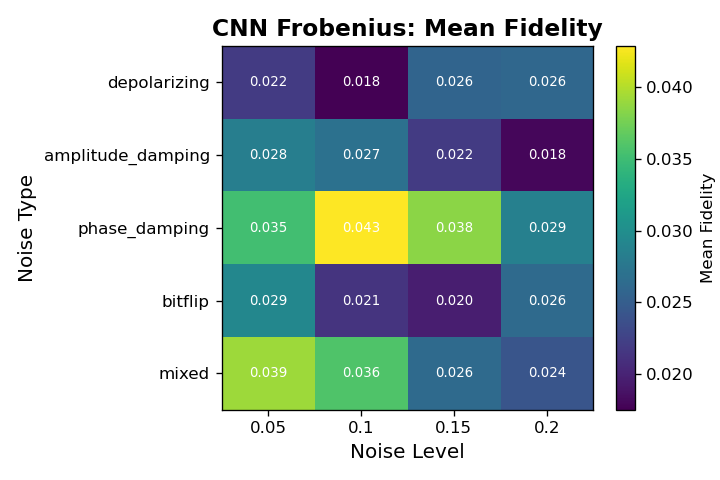
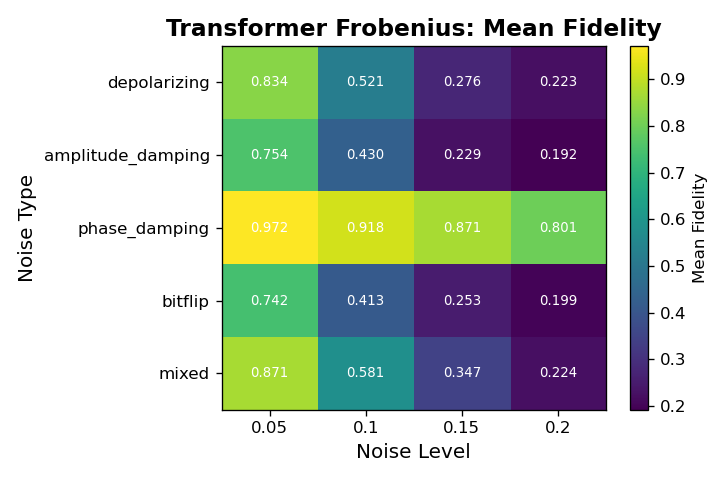
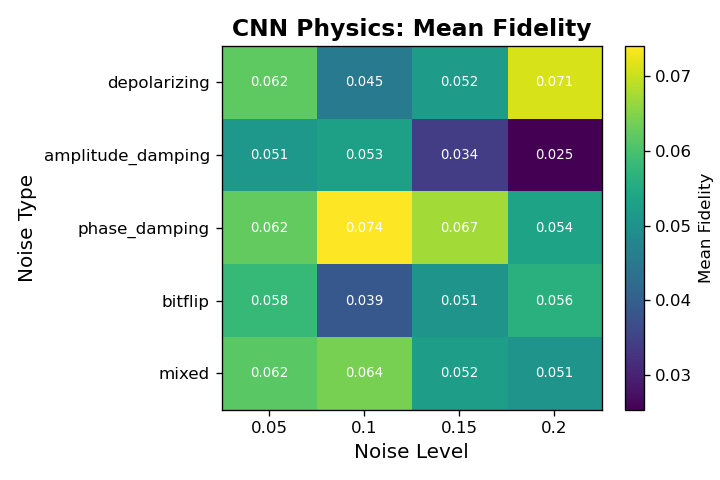
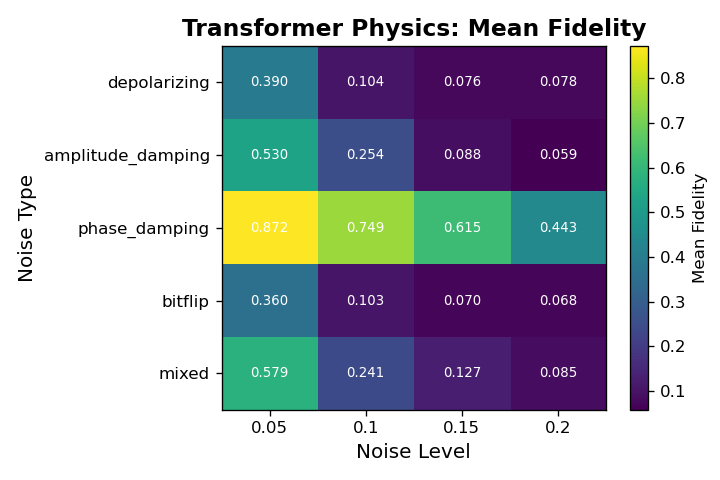 Across all architectures, fidelity varies systematically with both noise type and noise level, revealing clear differences in robustness among the four models. The CNN models achieve only marginal fidelity overall and show weak sensitivity to noise type, with values typically in the 0.02 to 0.05 range regardless of corruption. In contrast, the Transformer architectures display structured behavior: the Frobenius-loss Transformer consistently achieves the highest fidelity across nearly every noise cell, particularly for low-level phase damping and mixed noise, where it reaches its best performance. Its fidelity decays as the noise level increases, but it remains substantially above all CNN baselines. The physics-informed Transformer shows the opposite pattern. Although its absolute fidelity is lower than the Frobenius variant, it is markedly more stable across noise types and noise levels, exhibiting much smaller drops in fidelity as corruption increases. This indicates that the constraints enforced by the physics-informed loss improve robustness in high-noise regimes at the cost of peak performance in cleaner settings. Overall, these noise-resolved results show that Transformers not only outperform CNNs in denoising fidelity but also capture structure in the noise process itself, with the Frobenius variant excelling in low-noise cells and the physics-informed variant maintaining comparatively consistent behavior under stronger corruptions.
Across all architectures, fidelity varies systematically with both noise type and noise level, revealing clear differences in robustness among the four models. The CNN models achieve only marginal fidelity overall and show weak sensitivity to noise type, with values typically in the 0.02 to 0.05 range regardless of corruption. In contrast, the Transformer architectures display structured behavior: the Frobenius-loss Transformer consistently achieves the highest fidelity across nearly every noise cell, particularly for low-level phase damping and mixed noise, where it reaches its best performance. Its fidelity decays as the noise level increases, but it remains substantially above all CNN baselines. The physics-informed Transformer shows the opposite pattern. Although its absolute fidelity is lower than the Frobenius variant, it is markedly more stable across noise types and noise levels, exhibiting much smaller drops in fidelity as corruption increases. This indicates that the constraints enforced by the physics-informed loss improve robustness in high-noise regimes at the cost of peak performance in cleaner settings. Overall, these noise-resolved results show that Transformers not only outperform CNNs in denoising fidelity but also capture structure in the noise process itself, with the Frobenius variant excelling in low-noise cells and the physics-informed variant maintaining comparatively consistent behavior under stronger corruptions.
6.0.5. Failure Modes and Qualitative Analysis
A closer inspection of individual reconstruction failures reveals distinct failure modes tied to both architecture and loss design. The CNN models exhibit the most brittle behavior: when they fail, they typically collapse toward oversmoothed density matrices with attenuated off-diagonal structure, especially under high noise levels. This is consistent with their convolutional inductive bias, which cannot easily represent long-range correlations in the density matrix. The Frobenius-loss CNN is especially prone to this collapse, while the physics-informed CNN occasionally produces outputs that satisfy physical constraints but remain far from the true clean states, indicating that the added constraints can steer optimization without meaningfully improving reconstruction. The Transformer models fail in more structured ways. The Frobenius-loss Transformer sometimes produces sharp but globally misaligned reconstructions, suggesting that it has learned expressive global patterns but can be destabilized under heavy noise. The physics-informed Transformer exhibits the most “graceful” failures: even when fidelity drops, its outputs tend to retain Hermiticity, a well-formed eigenvalue spectrum, and approximately correct trace, confirming that the loss constraints operate as intended. These qualitative differences underline that architectural capacity governs how a model fails, while the loss function governs how bad those failures become.
7. Limitations
8. Conclusion
8.1. TODO Add conclusion
8.2. TODO Talk about the scalabitlity of each approach
9. References
Karan Kendre (2025). Machine Learning for Quantum Noise Reduction.